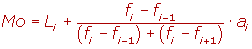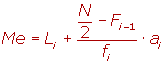En matemáticas, un alumno tiene las siguientes notas: 4, 7, 7, 2, 5, 3
n = 6 (número total de datos)
La media aritmética de las notas de esa asignatura es 4,8. Este número representa el promedio.
Ejemplo 2:
Cuando se tienen muchos datos es más conveniente agruparlos en una tabla de frecuencias y luego calcular la media aritmética. El siguiente cuadro con las medidas de 63 varas de pino lo ilustra.
Largo (en m)
|
Frecuencia absoluta
|
Largo por Frecuencia absoluta
|
5
|
10
|
5 . 10 = 50
|
6
|
15
|
6 . 15 = 90
|
7
|
20
|
7 . 20 = 140
|
8
|
12
|
8 . 12 = 96
|
9
|
6
|
9 . 6 = 54
|
|
Frecuencia total = 63
|
430
|
Se debe recordar que la frecuencia absoluta indica cuántas veces se repite cada valor, por lo tanto, la tabla es una manera más corta de anotar los datos (si la frecuencia absoluta es 10, significa que el valor a que corresponde se repite 10 veces).
Moda (Mo)
Es la medida que indica cual dato tiene la mayor frecuencia en un conjunto de datos; o sea, cual se repite más.
Ejemplo 1:
Determinar la moda en el siguiente conjunto de datos que corresponden a las edades de niñas de un Jardín Infantil.
5, 7, 3, 3, 7, 8, 3, 5, 9, 5, 3, 4, 3
La edad que más se repite es 3, por lo tanto, la Moda es 3 (Mo = 3)
Ejemplo 2:
20, 12, 14, 23, 78, 56, 96
En este conjunto de datos no existe ningún valor que se repita, por lo tanto, este conjunto de valores no tiene moda.
Mediana (Med)
Para reconocer la mediana, es necesario tener ordenados los valores sea de mayor a menor o lo contrario. Usted divide el total de casos (N) entre dos, y el valor resultante corresponde al número del caso que representa la mediana de la distribución.
Es el valor central de un conjunto de valores ordenados en forma creciente o decreciente. Dicho en otras palabras, la Mediana corresponde al valor que deja igual número de valores antes y después de él en un conjunto de datos agrupados.
Según el número de valores que se tengan se pueden presentar dos casos:
Si el número de valores es impar, la Mediana corresponderá al valor central de dicho conjunto de datos.
Si el número de valores es par, la Mediana corresponderá al promedio de los dos valores centrales (los valores centrales se suman y se dividen por 2).
Ejemplo 1:
Se tienen los siguientes datos: 5, 4, 8, 10, 9, 1, 2
Al ordenarlos en forma creciente, es decir de menor a mayor, se tiene: 1, 2, 4, 5, 8, 9, 10
El 5 corresponde a la Med, porque es el valor central en este conjunto de datos impares.
Ejemplo 2:
El siguiente conjunto de datos está ordenado en forma decreciente, de mayor a menor, y corresponde a un conjunto de valores pares, por lo tanto, la Med será el promedio de los valores centrales.
21, 19, 18, 15, 13, 11, 10, 9, 5, 3
Ejemplo 3:
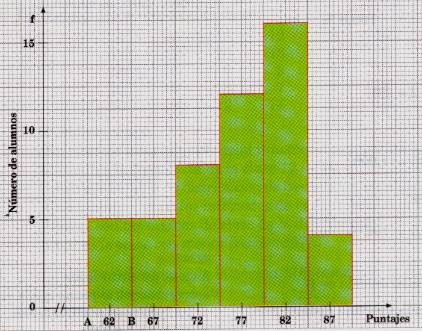
Interpretando el gráfico de barras podemos deducir que:
5 alumnos obtienen puntaje de 62
5 alumnos obtienen puntaje de 67
8 alumnos obtienen puntaje de 72
12 alumnos obtienen puntaje de 77
16 alumnos obtienen puntaje de 82
4 alumnos obtienen puntaje de 87
lo que hace un total de 50 alumnos
Sabemos que la mediana se obtiene haciendo
lo cual significa que la mediana se ubica en la posición intermedia entre los alumnos 25 y 26 (cuyo promedio es 25,5), lo cual vemos en el siguiente cuadro:
puntaje
|
alumnos
|
62
|
1
|
62
|
2
|
62
|
3
|
62
|
4
|
62
|
5
|
67
|
6
|
67
|
7
|
67
|
8
|
67
|
9
|
67
|
10
|
72
|
11
|
72
|
12
|
72
|
13
|
72
|
14
|
72
|
15
|
72
|
16
|
72
|
17
|
72
|
18
|
77
|
19
|
77
|
20
|
77
|
21
|
77
|
22
|
77
|
23
|
77
|
24
|
77
|
25
|
77
|
26
|
77
|
27
|
77
|
28
|
77
|
29
|
77
|
30
|
82
|
31
|
82
|
32
|
82
|
33
|
82
|
34
|
82
|
35
|
82
|
36
|
82
|
37
|
82
|
38
|
82
|
39
|
82
|
40
|
82
|
41
|
82
|
42
|
82
|
43
|
82
|
44
|
82
|
45
|
82
|
46
|
87
|
47
|
87
|
48
|
87
|
49
|
87
|
50
|
El alumno 25 obtuvo puntaje de 77
El alumno 26 obtuvo puntaje de 77
Entonces, como el total de alumnos es par debemos promediar esos puntajes:
La mediana es 77, lo cual significa que 25 alumnos obtuvieron puntaje desde 77 hacia abajo (alumnos 25 hasta el 1 en el cuadro) y 25 alumnos obtuvieron puntaje de 77 hacia arriba (alumnos 26 hasta el 50 en el cuadro).
 llamado centro de gravedad.
llamado centro de gravedad.